


RLHF to train your baby chatGPT?

I recently was able to train my first model using Reinforcement Learning Through Human Feedbacks (RLHF). This was thanks to the excellent TRL module from HuggingFace. I simply followed their example to fine-tune a GPT-2, which already wrote movie reviews, to make it write more positive movie reviews. The training is done via RLHF which according to the consensus if how chatGPT was trained. The TRL library, according to HuggingFace’s documentation, is based on the original Ziegler 2020 paper. It took me 2 hours to fine tune the GPT-2-imdb using RLHF on my RTX 2080 ti. Here is a screen shot of the results:
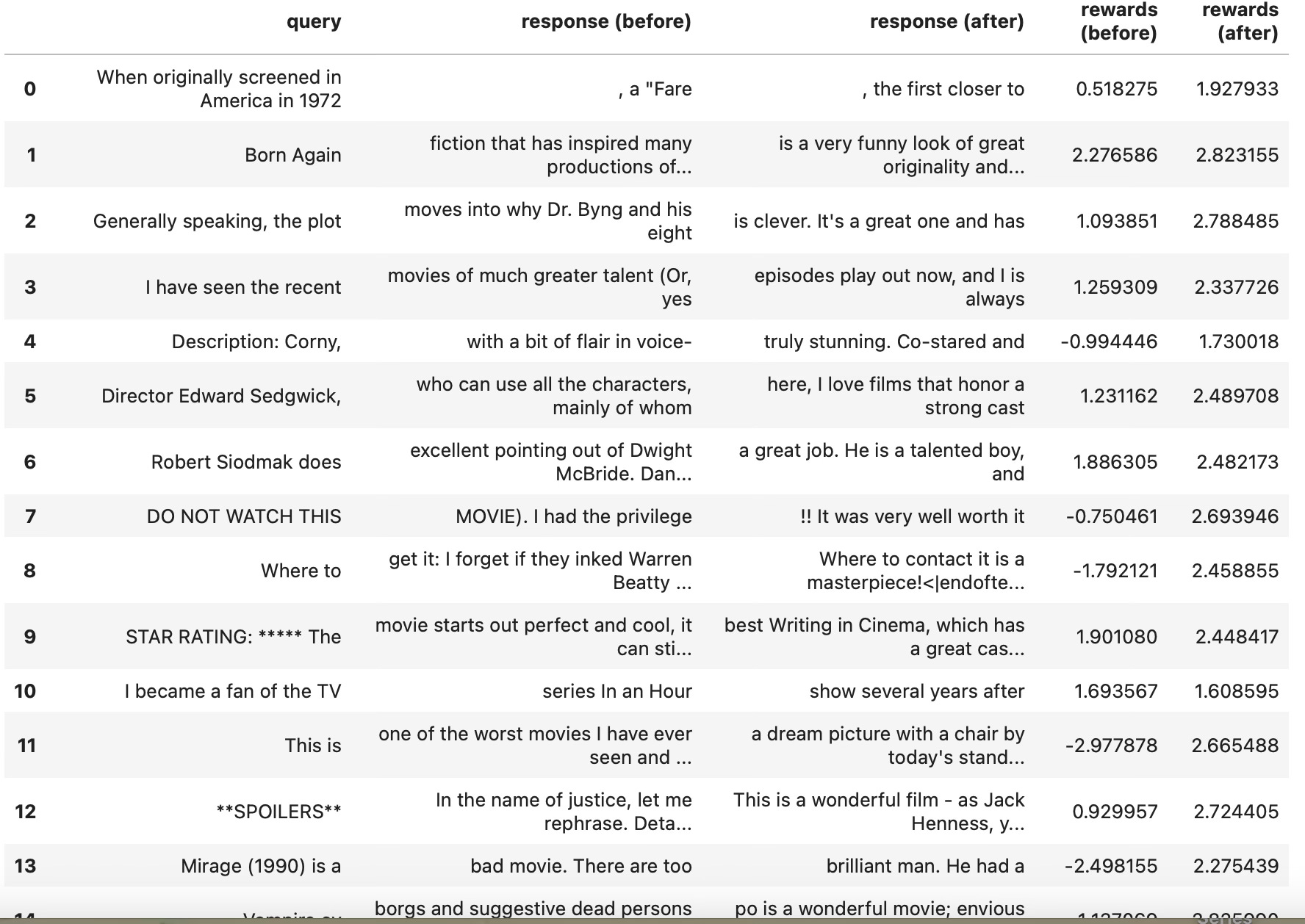
I think it worked!
Their example is clever. They use a BERT sentiment scorer from the HF hub as the reward function and it works.
Why is this important?
I think with this pipeline, and TRL library, we are all getting closer to building our own chatGPTs and to advance deep learning research. We basically can now use our own data to fine tune GPTs through RLHF. I find this is so important that I wanted to write this article to share this tool.
Resources
You can find all the links to related papers and libraries from my GitHub here: https://github.com/rcalix1/RLHF
YouTube:
TRL and similar modules also support multiple GPU processing. My students and I are still working on that part and I will provide updates if we make some progress.
And if you are just getting started with HuggingFace, or machine learning, I recommend the following resources:
Keep updated of AI developments and products at:
And the HuggingFace website has really great materials as well.
https://huggingface.co
Let me know if you know of any other good resources.
Author: Ricardo A. Calix, Ph.D.
My New Book On-Line: Link
FTC and Amazon Disclaimer: This post/page/article includes Amazon Affiliate links to products. This site receives income if you purchase through these links. This income helps support content such as this one. Content may also be supported by Generative AI and Recommender Advertisements.
My Deep Learning Books on Amazon: Book
Sponsored Links:
For more on AI products and information: The AI Hub
Follow my YouTube Channel